
* well, a bit more than a day 🙂
Some time ago, I wrote some automation for Softcatalà‘s website, aimed to automatically update some software download information that we offer on the site.
That piece of code was at the very bottom of my “list of code to be proud of”. Even if it was a relatively small, less than 1000 lines PHP single file, it was bad. It was, basically, breaking every single best practice and design principle that you can think of. Taking the SO from SOLID, as an example:
- Single Responsibility: That code was doing a ton of things. Downloading data from third-party APIs, mangling data, parsing CSV, JSON and XMLs, updating WordPress’ database, reusing some preprocessed (with BASH/SED/GREP/…) text files…
- Open-closed: Every time we wanted to add some new automation? We had to touch that file (and a few of the methods in it). Firefox decided to change how they release new versions? We had to touch that file. WordPress changed its internal DB structure? We had to touch that file….
And the worst thing: every time any change happened here, the whole website had to be deployed. Pretty nasty, right?
The last straw

A few days ago, together with some of my colleagues at Softcatalà, we were cleaning up some content on the site. Broken links, software that doesn’t exist anymore, outdated versions…. And we identified two pretty important programs that we were still updating manually every time a new version is released: GIMP and Inkscape.
So I just opened the PHP file, did some copying and pasting from other places, and hacked together the automation in less than one hour. Done, right?
Wrong! When doing that, I couldn’t stand the amount of code repetition that I had just introduced.
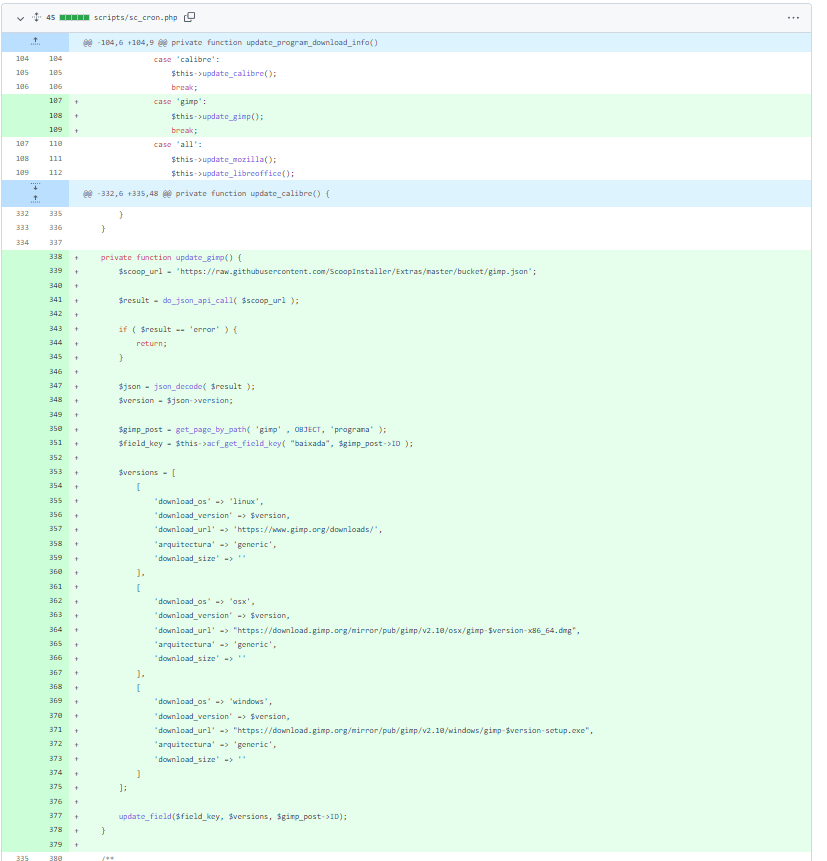
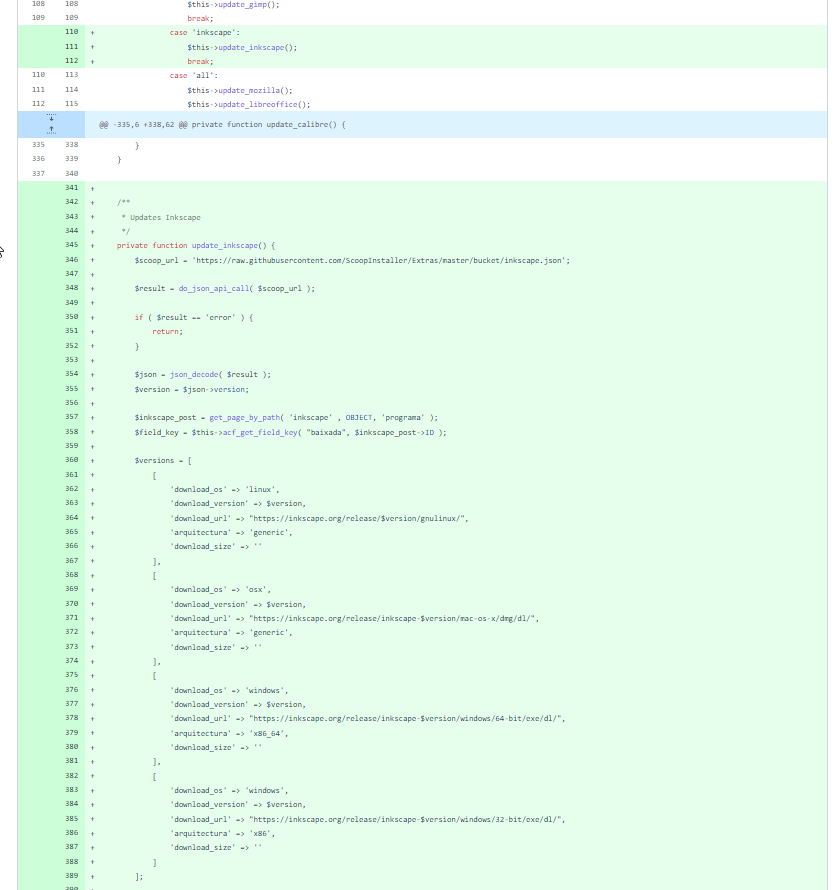
Without looking too deeply at the code, you’ll be able to see how repeated the code is. And one of the reasons is that, after spending almost half an hour trying to find the best way of knowing when each program released a new version, I decided to just leverage Scoop1For those of you who don’t know, Scoop is a Windows command-line installer. Something somewhat close to Debian’s APT package manager, but for Windows.‘s metadata files. So now I had a new pattern, definitely not DRY2Don’t repeat yourself, another important software development principle, but much easier and scalable.
Ubuntu, the first rewrite
Then, I realized that we had our Ubuntu updater broken. The PHP code was relying on a pre-process done by another script (BASH in this case), where Ubuntu’s releases page was being downloaded and parsed to extract links.
Recently, Canonical added a new support mode for Ubuntu, Extended Security Maintenance, with a section on that page. Combined with two overlapping supported release (21.04 and 21.10), our hacky and fragile HTML extractor failed to identify the “last” release. We were offering downloads for 14.04 (7½ years old!) instead of for 21.10 ?

To make things even worse, that was only working for Ubuntu Desktop. But all other flavors (KUbuntu, XUbuntu, Ubuntu-Mate…) had their own download page, with a different HTML to parse.
And at that point I decided to build a lightweight microservice that would replace the bash script, but better. Instead of doing a partial data mangling into a CSV to, then, hand it over to the PHP updater, it would be a REST API that would expose just what we really need. It would have exactly the information required to update our pages: a set of download URLs (and optionally file size) for a given operating system & architecture, with the version number.
On top of that, I didn’t want to just rewrite the fragile HTML parsing. And I was sure that had to be a known (and solved issue). And I thought of something Alejandro always says:
If you search for something in StackOverflow and you don’t find the answer, you have a hard problem to solve. But if you don’t find the question, your problem is wrong.
Et voilà! I found a couple of Python libraries (ubuntu-iso-download and ubuntu-release-info) that were doing exactly that: not only they were providing the different versions, but also were handing over the final URLs for each Ubuntu Flavor. That was exactly what I needed!
The discovery of those libraries had another side effect: I wasn’t really sure which tech stack I was going to use to write the microservice, but know the language was clear, Python. And Flask seemed the easiest choice to build a lightweight REST API on top of it.
Less than half an hour later, I had a very first version of the service, exposing the information I needed from the PHP script to update WordPress.
Deploying the service
The next step was to deploy the service somewhere, so that the script could get that information. We have a docker-based infrastructure, with Traefik as a reverse proxy, that makes it extremely easy to add and route microservices. And we have CI/CD, so it’s also fast to deploy: with a few Gitlab pipelines, a simple python script, a Go web service and using incrond, new services are alive in a matter of few minutes.
But we rely a lot on our Gitlab instance to build (and host) the Docker images, etc. And given that the code was going to be open-sourced from minute 1, and hosted on Github, why not leverage GitHub Actions?
Less than a month ago, I wrote my first GitHub workflows to do something very similar for Apertium Apy3Apertium Apy is a web service on top of the free machine translation engine Apertium (another open-source project I contribute to). A few minutes later (and a couple of failed image builds due to typos on the secrets), the image was pushed into GitHub’s Container Registry, and deployed in our infrastructure.
Refactoring and clean up
Once I had the MVP of the project up and running, and before I started migrating more “updaters”, I went back to the drawing board. There were a couple of things I need to re-think before writing anything else.
Originally, my idea was to build a small microservice for each updater, which would give me a lot of isolation. I could take two approaches: multiple deployments or a single docker-compose for all of them. But in any case, the deployment overhead was too big, and that made me rethink it. Also, in most cases, the amount of non-boilerplate code each updater would have would be minimal. It was clearly not worth.
I spend some time refactoring the Ubuntu code and preparing it to be more modular. I wanted to make adding new updaters easy, and not to require touching any (or almost any) existing file. The codebase ended up with a top level handler.py file, with only Flask route registration, and a module for each updater.
After that, I started porting incrementally over the code in the PHP file to this Python package, one updater at a time. Some of the modules are very unique, like Ubuntu’s (using a couple of libraries to make things easier), Calibre’s (using an RSS parser to extract the latest version). Some others are pretty similar (Inkscape & GIMP, pulling version number from Scoop and building URLs following a known pattern.
I also extracted some code into generic functions. For example, one that gets the file size by doing HEAD requests to the URLs, or converting those sizes (in bytes) to a human-friendly size (using KB, MB or GB). And I wrote some tests, and integrated them into the CI/CD.
Cleaning up the PHP file
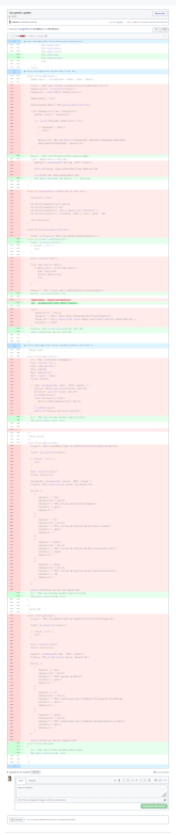
As I was moving more code into the service, and new versions of it were being deployed, I was updating the PHP script. I had to test if it was still working properly.
Even if I was anticipating how the PHP script would look like, it’s still shocking to see the result. This screenshot shows the changes when I migrated Ubuntu, Callibre, GIMP and Inkscape to use the new API. Deleting code is one of my favorite parts of programming!
Obviously, it’s not a totally fair comparison: some of that code hasn’t really disappeared, and instead now lives in the Python microservice. But most of it is actually gone.
By having all programs sharing the same contract in the API, each updater is now two lines in the PHP side: one to specify the web service’s endpoint, and another one to call a generic function to update the database.
Next steps
After having the microservice pretty much ready (only Mozilla left), I realized something. The PHP code became a mapping of WordPress post slugs with the service endpoint to gather the data. Pretty simple, but still a bit annoying. Because adding a new updater would require writing code in the Python web service, and adding the mapping to the PHP code (and deploying the website).
When we add a new updater, we already know the page to update, so it doesn’t really matter where that goes. So I started writing another endpoint in the service that would expose that mapping.
Using a very naive repository, each module registers all programs that it knows about. Ubuntu registers all Ubuntu flavors and LibreOffice also registers help package, for example. And then the endpoint just gets everything from the repository.
The next step will be to swap who drives the process. Right now, the PHP script knows which programs it has to update. It calls the right endpoint for each of them, and executes the update. By just adding a previous step (PHP asking the service which programs to update), that can be reversed.
So in the near future, just by adding some new module in the service will be enough. The PHP script will discover that new updater, and will just use it. No more need to do a website deployment every time we want to automate something new!
The header image was created by Four Blair Services Pvt. Ltd., and is used under a CC-BY license.
{kind=link}
0 comentaris a «Building a microservice in a day*»